TidalSpace technology is the multi-layer AI infrastructure behind the TidalSpace companion app and Tidal Seal hardware — a stack of large language models, neural voice synthesizers, real-time inference servers, and a device communication layer over BLE 5.3. This article is our transparent breakdown of what runs where, how fast it is, and where we make deliberate tradeoffs between quality, speed, and cost.
The architecture at a glance
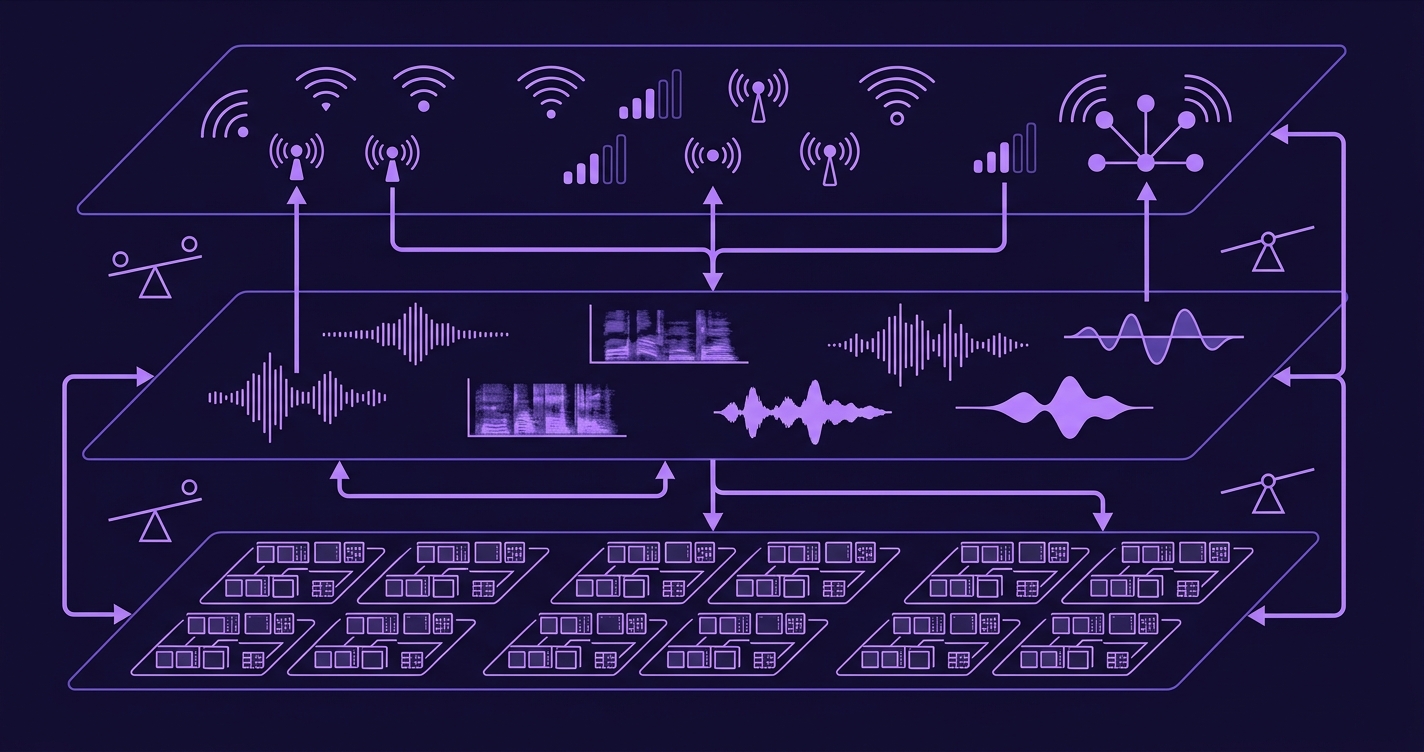
TidalSpace has four distinct processing layers, each with its own latency budget, infrastructure, and failure isolation:
| Layer | What it does | Where it runs | Typical latency |
|---|---|---|---|
| 1. Client | UI rendering, input capture, wake word detection | On-device (phone or Tidal Seal) | 10–50ms |
| 2. ASR | Voice-to-text transcription | Cloud GPU (streaming) | 200–400ms |
| 3. LLM | Conversation reasoning, personality, memory retrieval | Cloud GPU (A100/H100 cluster) | 300–700ms |
| 4. TTS | Text-to-speech synthesis with character voice | Cloud GPU (dedicated TTS nodes) | 150–300ms |
For text-only conversations, only layers 1 and 3 are active. For voice calls, all four fire in sequence with streaming between them to minimize total wait time. The Tidal Seal hardware adds a BLE relay (under 50ms) and on-device wake word detection (under 200ms).
The LLM layer: model selection and fine-tuning
TidalSpace does not rely on a single model. We use a multi-model routing system that selects the best model for each interaction based on complexity, context length, and required response speed.
- Lightweight model (8B parameters) — Used for quick responses, greetings, and short exchanges. Optimized for sub-400ms inference. Fine-tuned on conversation data for personality consistency.
- Medium model (30–40B parameters) — The default for most conversations. Balances quality and speed at 500–700ms inference time. Fine-tuned for emotional nuance, long-term memory integration, and character depth.
- Heavy model (70B+ parameters) — Engaged for complex reasoning, multi-turn storytelling, and deep emotional conversations. Takes 700–1200ms but produces noticeably richer output. Used selectively to manage GPU cost.
The routing decision happens in under 10ms and is based on the current conversation context, the character's personality intensity setting, and the user's historical engagement pattern. Users on the free tier see the lightweight model more often; Pro subscribers get the medium model as default with the heavy model available for peak moments.
The single biggest engineering decision we made was separating the character memory layer from the model. This means we can upgrade the underlying LLM without your companion forgetting who you are. The trade-off is increased inference complexity — every response requires a memory retrieval step before generation — but the user experience benefit is worth it.
Memory: the persistence layer
Long-term memory in TidalSpace is not stored inside the LLM's weights. It is a separate structured database that the LLM reads from at inference time. This architecture has three components:
- Episodic memory — A chronological log of significant conversation events. "You mentioned your dog's name is Max on March 12." Stored as structured key-value pairs with timestamps and emotional valence tags.
- Semantic memory — Distilled facts about the user. "You prefer morning conversations. You work in software. You dislike small talk." These are extracted from episodic memory by a background process that runs after each session.
- Character profile — The personality definition, backstory, and behavioral parameters that you set when creating or customizing your AI character. This is user-owned and editable at any time.
At inference time, the system retrieves the top-K most relevant memories (typically 15–30 entries) and injects them into the LLM's context window alongside the recent conversation history. This is why TidalSpace characters can reference things you said months ago — the memory is being actively consulted, not just hoped-for from the model's training data.
For more on how memory works in practice, see our article on AI companion long-term memory. If you want to understand how this infrastructure enables real-time voice AI companions, see our dedicated voice overview.
Voice synthesis: the TTS pipeline
TidalSpace's voice synthesis uses a two-stage neural TTS system:
- Acoustic model — Converts text to a mel-spectrogram, capturing prosody, emphasis, and emotional tone. This model is conditioned on the character's voice profile and the emotional context of the response.
- Vocoder — Converts the mel-spectrogram to raw audio waveforms. We use a neural vocoder trained on high-quality speech data, producing 24kHz audio with natural breath patterns and micro-pauses.
Each character in TidalSpace can have a unique voice. Users on the Pro tier can fine-tune voice parameters including pitch range, speaking rate, and expressiveness. The voice is generated per-response — there is no pre-recorded audio. This means every sentence is fresh, but it also means voice quality depends on the TTS model's ability to handle the specific text being generated.
Latency optimization for voice
The key to responsive voice calling is streaming. TidalSpace does not wait for the full LLM response before starting TTS. Instead:
- The LLM streams tokens as they are generated.
- The TTS system begins synthesis after receiving the first 8–12 tokens.
- Audio chunks are streamed to the client as they are produced.
- The user hears the beginning of the response while the LLM is still generating the end.
This streaming pipeline reduces perceived latency by 40–60% compared to a batched approach where the full response is generated before any audio plays.
The Tidal Seal hardware connection
Tidal Seal connects to the TidalSpace infrastructure through a lightweight relay. The device handles:
- Wake word detection — Runs a small on-device model (under 5MB) that listens for the character's name or a custom wake phrase. This runs entirely locally for privacy.
- Audio capture and playback — A MEMS microphone array captures speech, and a 2W speaker plays synthesized audio. Audio is compressed using Opus codec at 24kbps before BLE transmission.
- Presence light — An RGB LED ring that glows in the character's signature color pattern. The light state is computed locally based on the character's emotional state, which is synced from the cloud.
- BLE 5.3 + Wi-Fi — BLE is used for initial pairing and low-bandwidth status updates. Wi-Fi carries the actual voice data. The device automatically switches to Wi-Fi when a voice session begins.
Tradeoffs we have made (honestly)
Engineering is about tradeoffs. Here are the ones we have chosen and why:
| Tradeoff | What we chose | Why |
|---|---|---|
| On-device vs cloud inference | Cloud | Current mobile hardware cannot run 30B+ parameter models at acceptable speed. On-device models produce noticeably worse conversation quality. |
| Model size vs latency | Multi-tier routing | We could use the 70B model for everything, but it would be 2–3x slower and 5x more expensive. Routing lets us use the right model for each moment. |
| Memory depth vs context window | Retrieval-based memory | stuffing all memories into the context window is expensive and degrades with scale. Retrieval is more complex but scales better. |
| Voice quality vs speed | Streaming with slight quality trade-off | We could produce higher-quality audio in batch mode, but the latency would be unacceptable for conversation. Streaming means the first syllable reaches you faster, even if the overall audio is marginally less polished. |
| Cost vs accessibility | Freemium with tiered model access | Running GPU inference is expensive. We offer a free tier with the lightweight model so anyone can try TidalSpace, but heavier models require a Pro subscription to keep the service sustainable. |
Infrastructure and reliability
TidalSpace runs on a multi-region GPU cluster with automatic failover. Key infrastructure facts:
- Servers: Dedicated GPU instances across three geographic regions (US-West, US-East, EU-West) to minimize network latency.
- Uptime target: 99.9% for text, 99.5% for voice (voice has more failure points — ASR, TTS, and audio streaming).
- Data encryption: TLS 1.3 in transit, AES-256 at rest. Voice recordings are deleted after 30 days unless opt-in for longer retention.
- Scaling: Auto-scaling GPU pools based on real-time concurrent session count. Peak capacity handles 3x average load.
Experience the TidalSpace stack
Text and voice conversations, long-term memory, and Tidal Seal hardware.
Get TidalSpace →